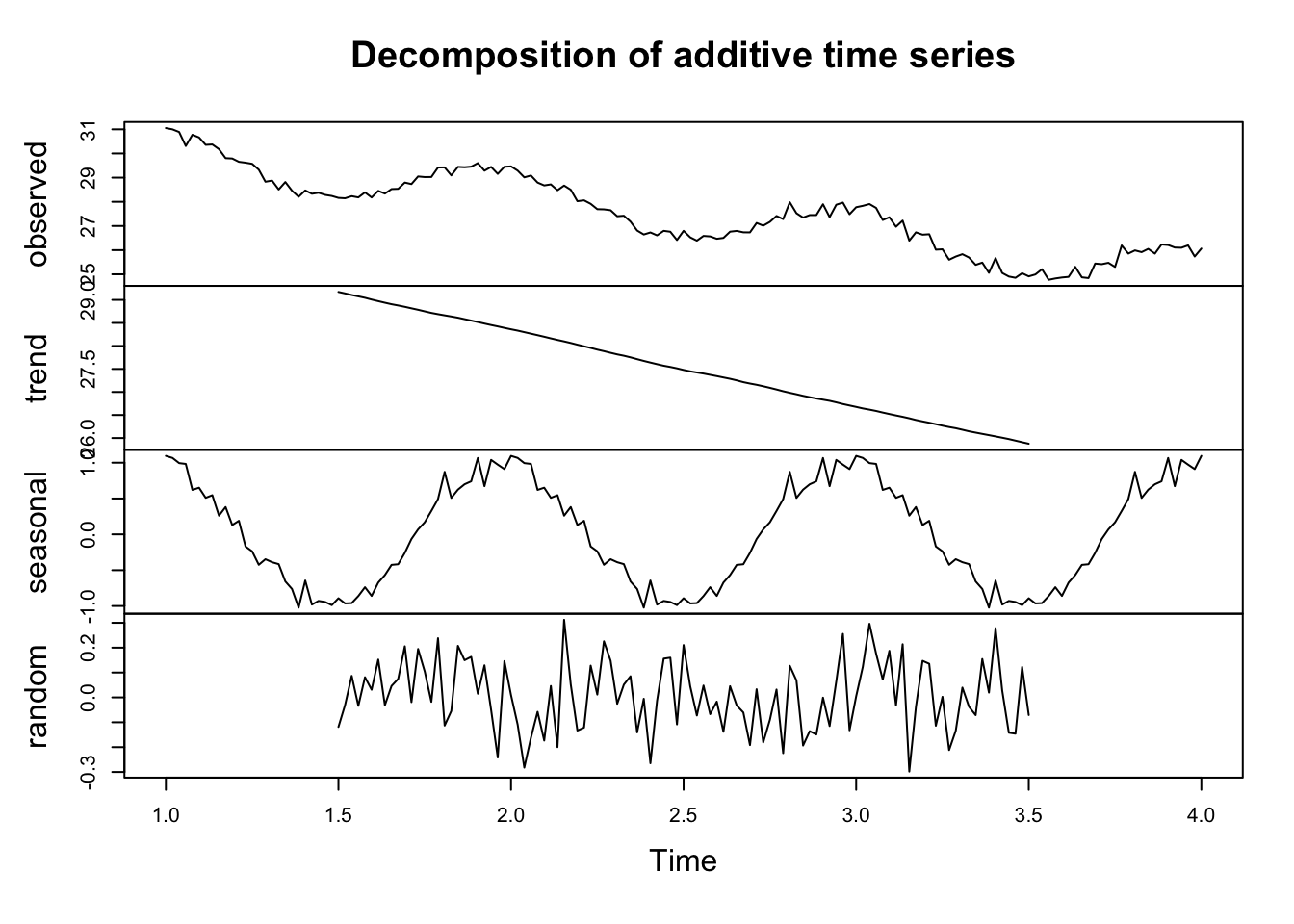
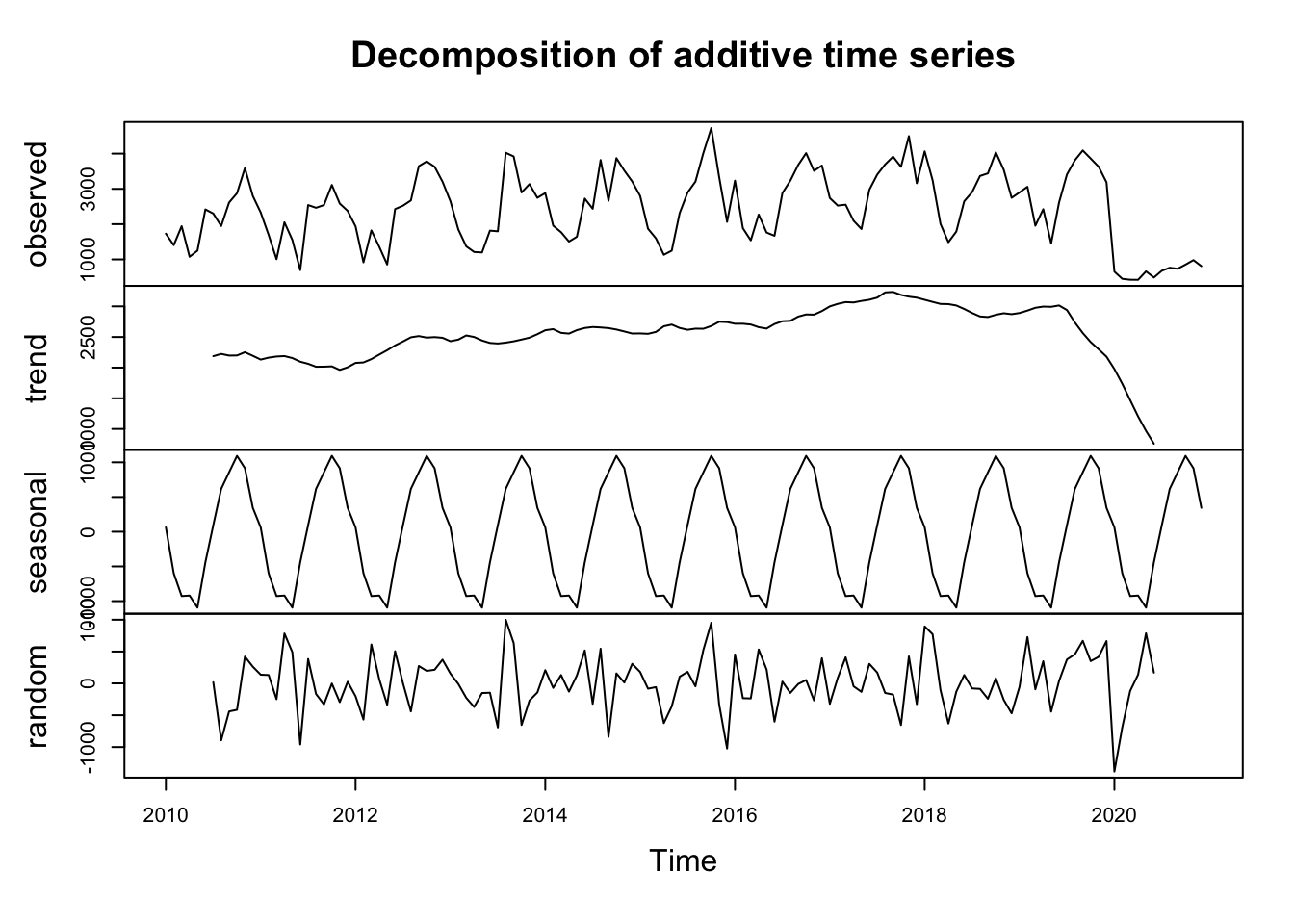
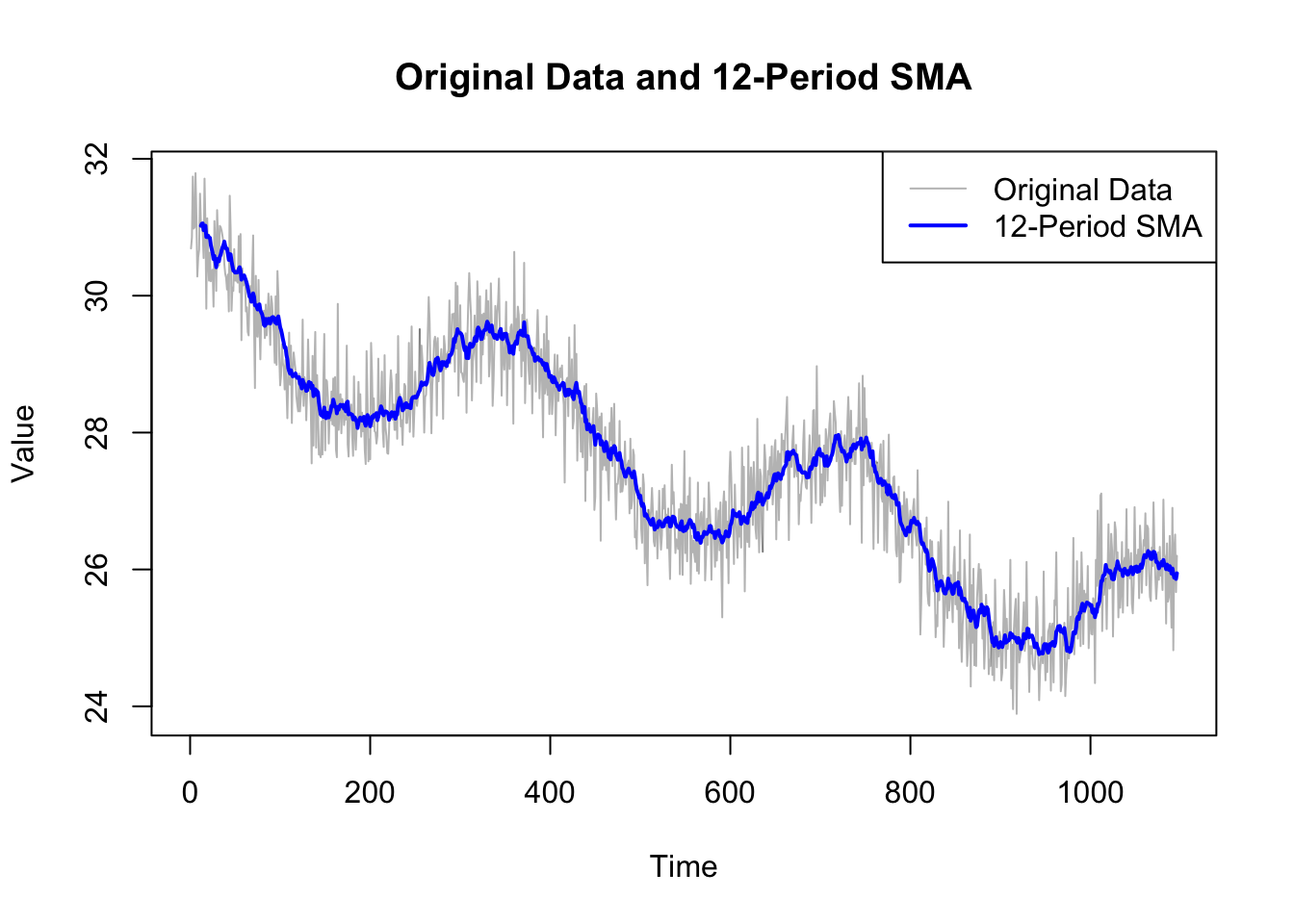
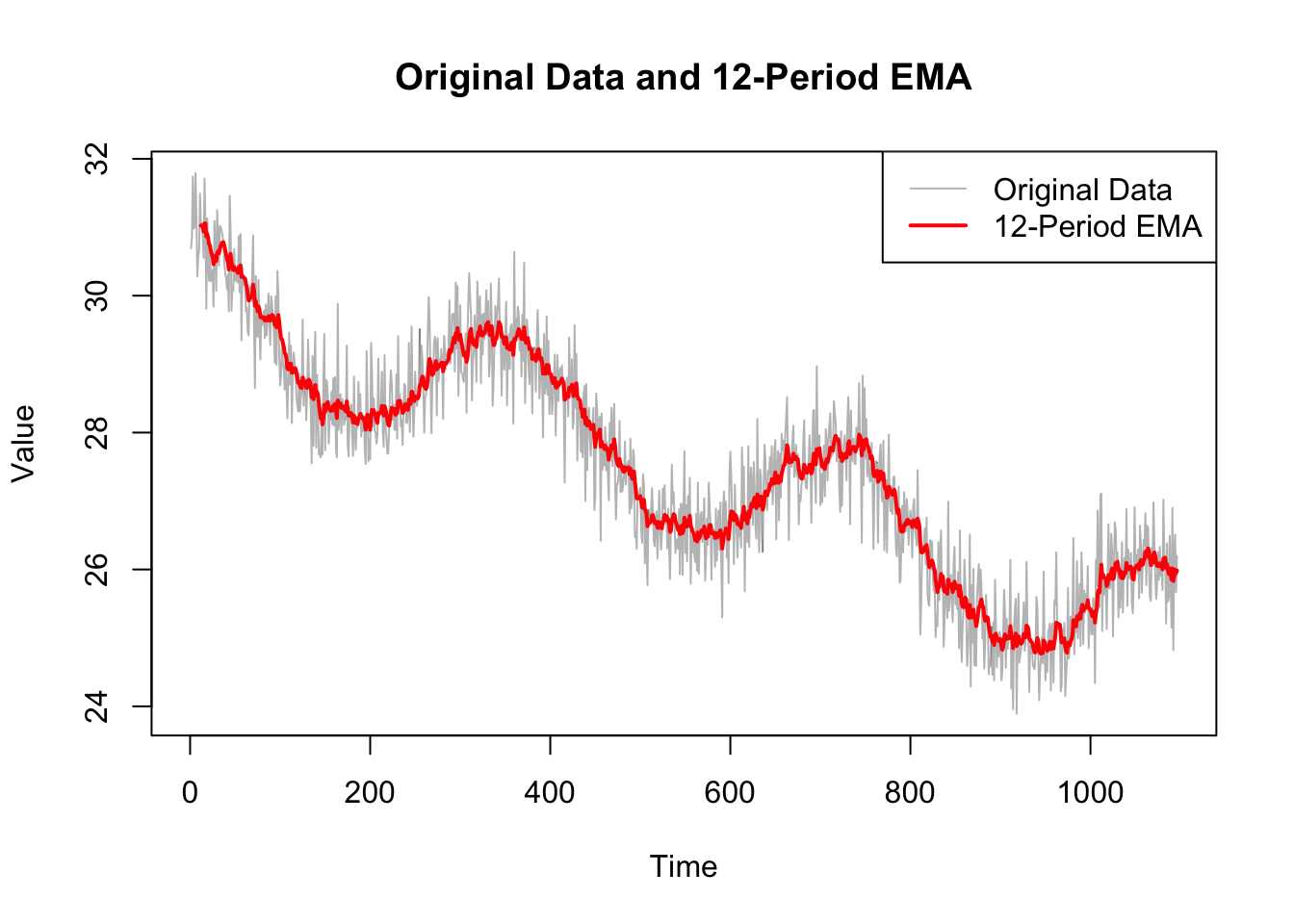
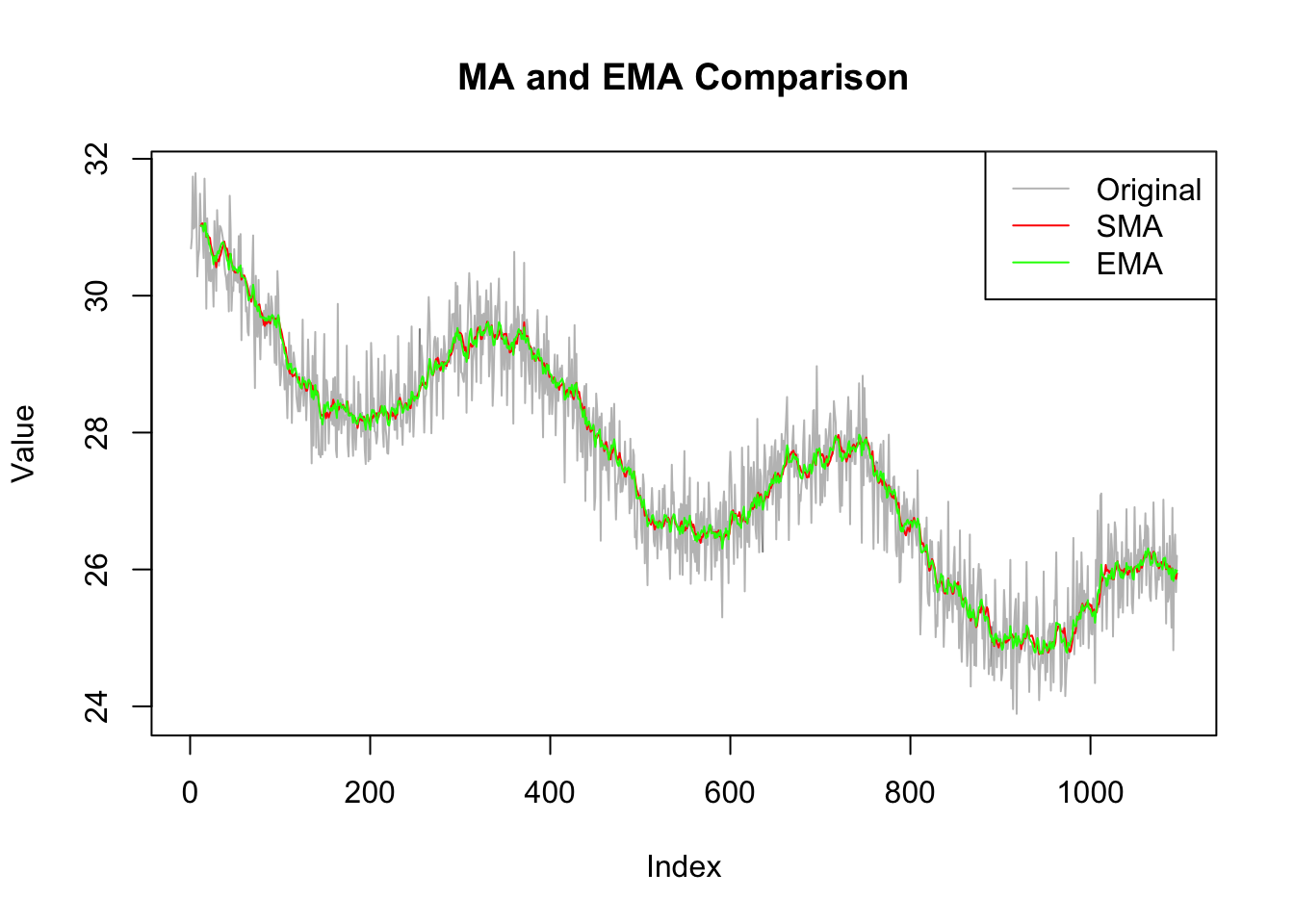
In an additive model, the observed time series is assumed to be a sum of the components. This is mathematically represented as: \[
Yt = Tt + St + It
\]
where $Yt is the observed data, $Tt is the trend component, $St is the seasonal component, and $It is the irregular or residual component.
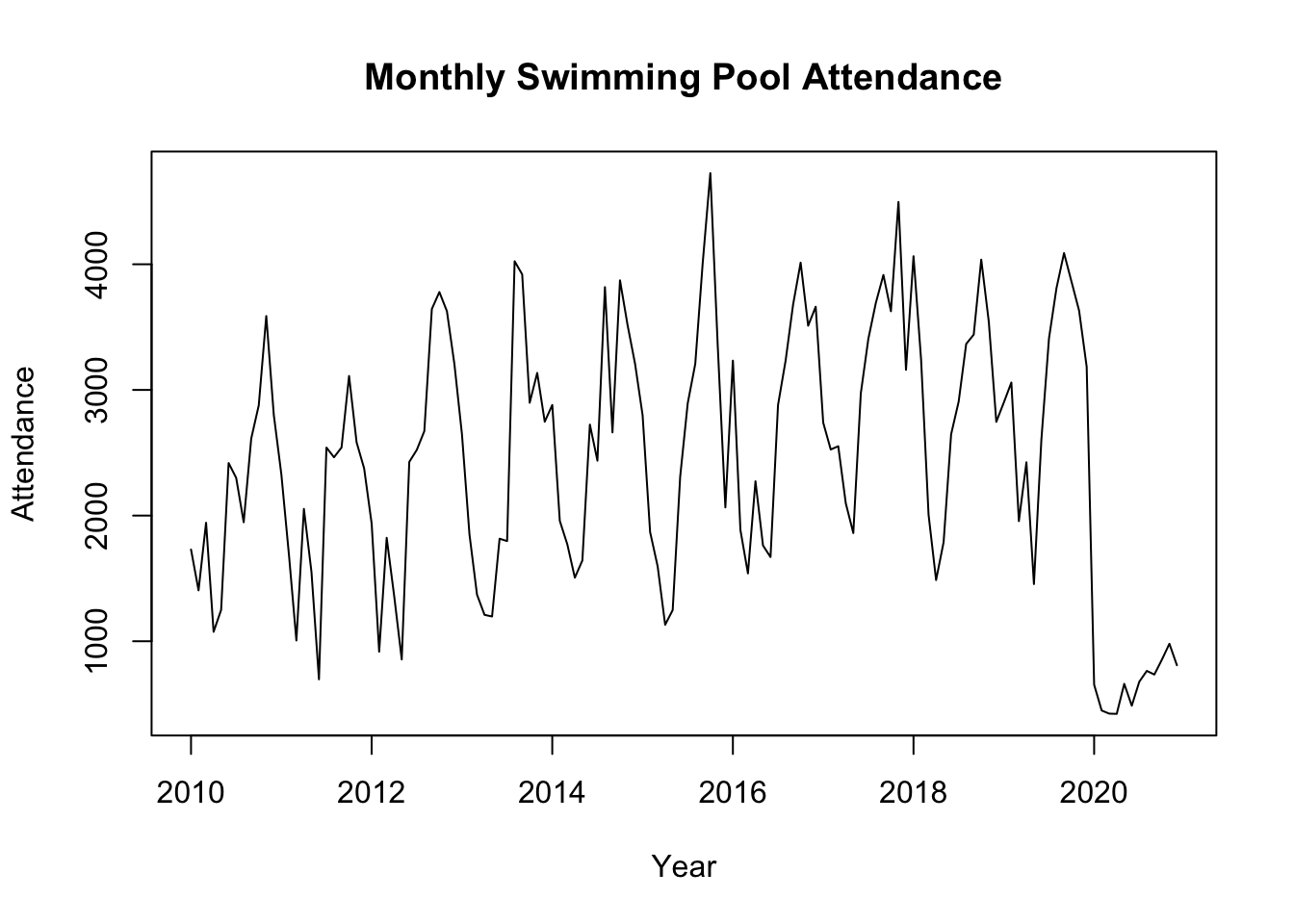
This model is typically used when the seasonal variations are roughly constant over time, meaning they do not change in proportion to the level of the time series.
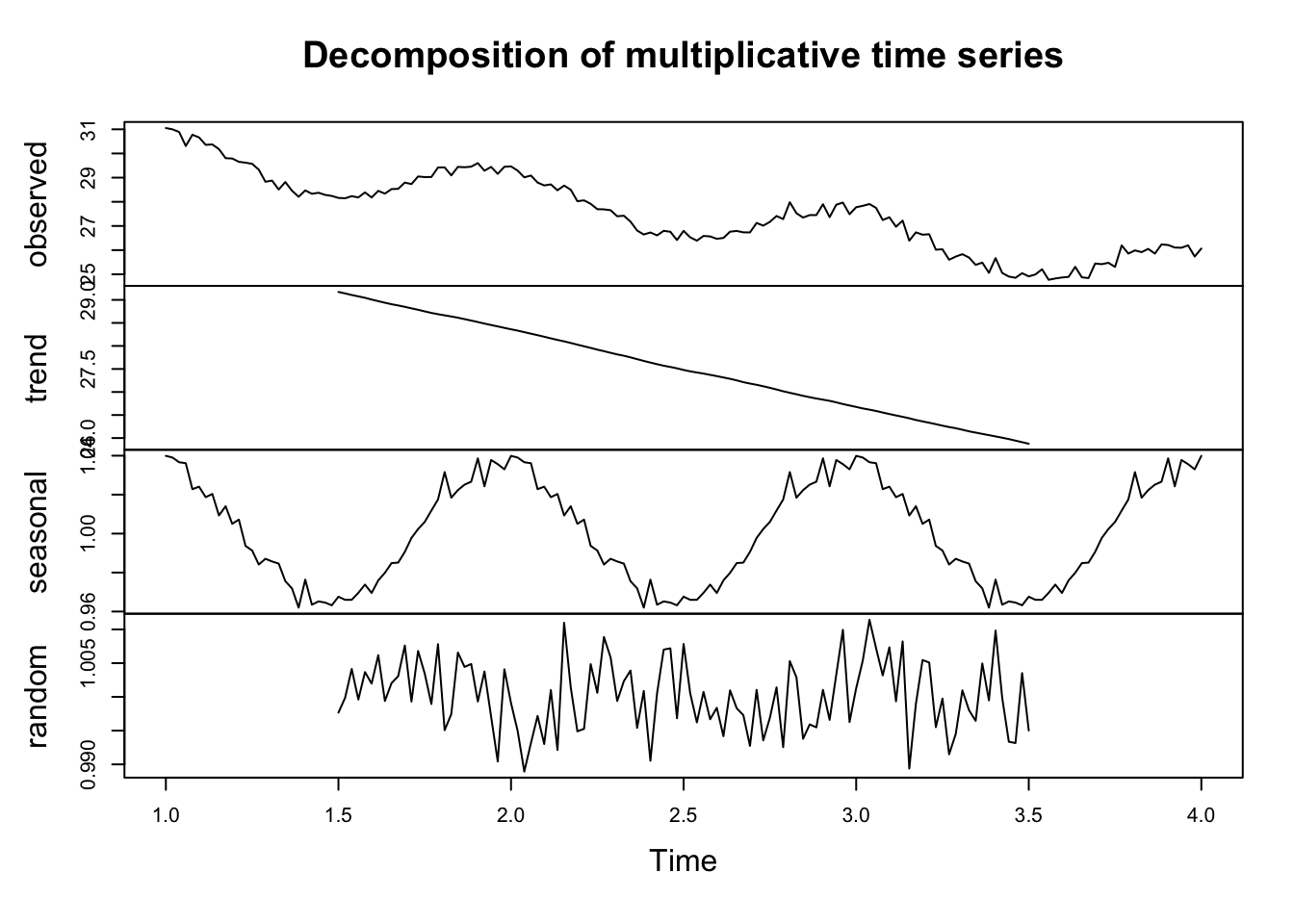
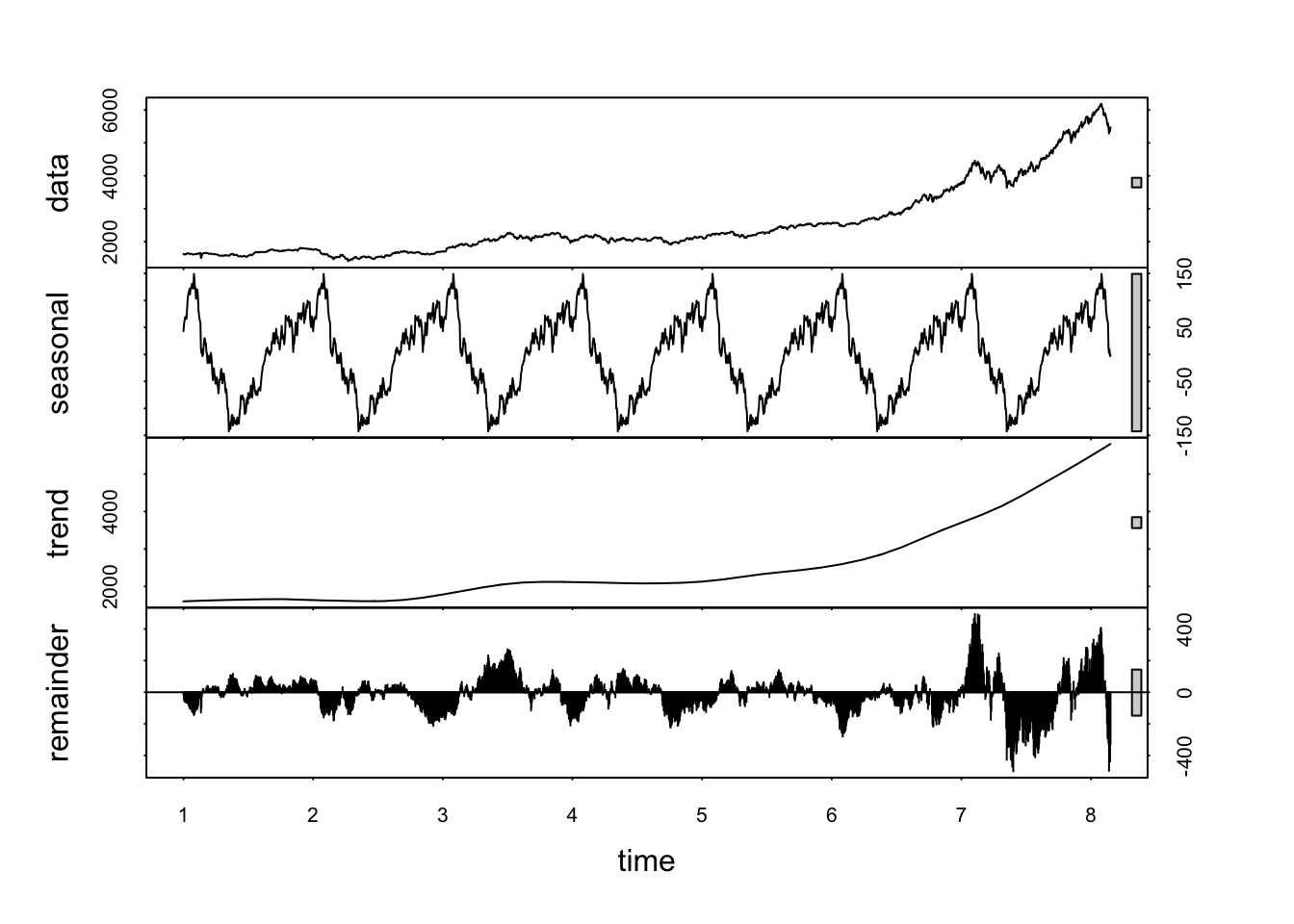
In a multiplicative model, the components are multiplied together instead of being added. The multiplicative model is represented as: \[
Yt =Tt × St × It
\]
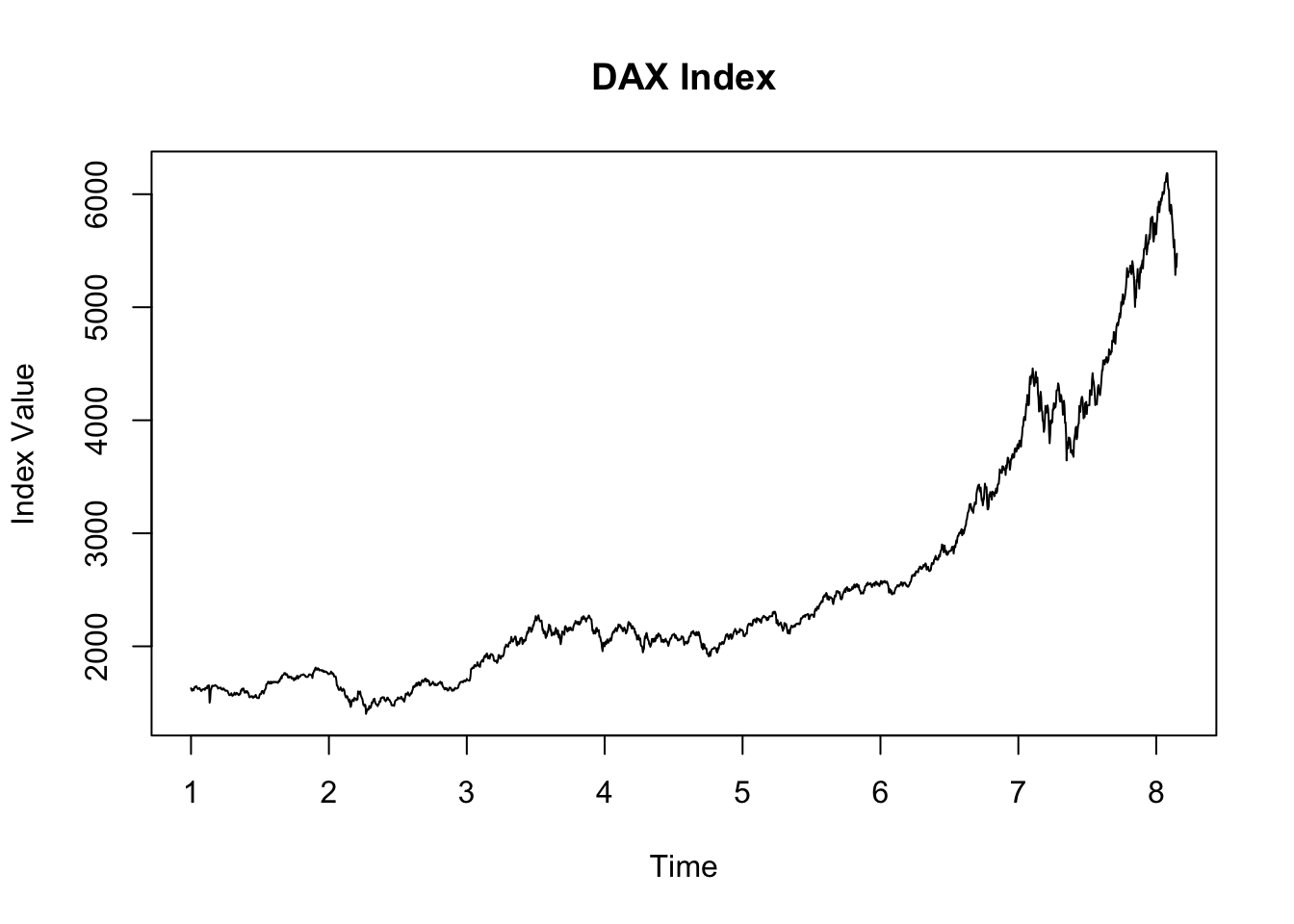
This model is suitable when the seasonal variations are changing proportionally with the level of the time series. In other words, the seasonal effect is a percentage of the trend, and thus, the seasonal amplitude increases or decreases over time as the data values increase or decrease.
The choice between using an additive or multiplicative decomposition model depends on the nature of the time series data. The additive model is more appropriate for linear relationships where the seasonal fluctuations and trends are consistent over time. In contrast, the multiplicative model is better suited for nonlinear relationships where the seasonal effect varies proportionally with the level of the time series.